Bi-Real Net
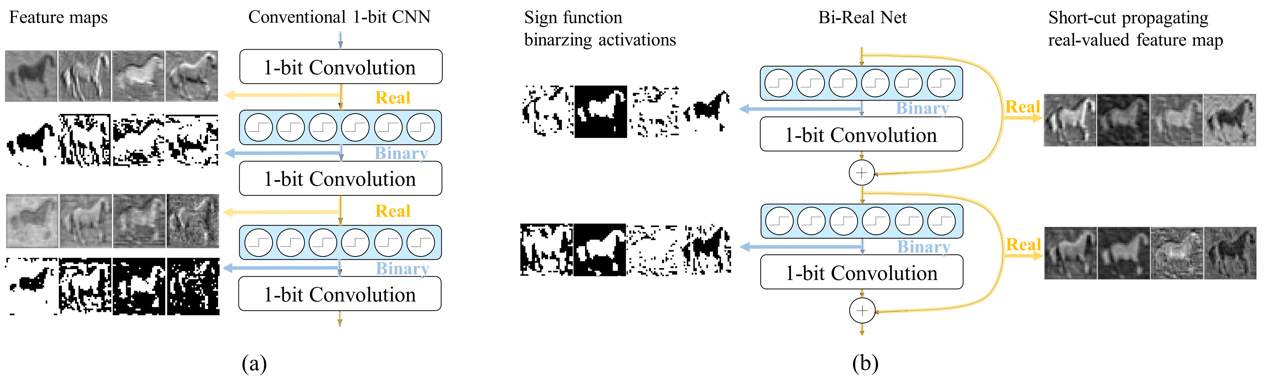
Deep convolutional neural networks (CNNs) are powerful but cumbersome. For implementing CNN
on mobile devices, compressing a CNN is highly needed. We study CNN compression via
binarization, network channel pruning and neural architecture search.
The so-called 1-bit convolutional neural networks have binary weights and binary
activations. While efficient, the lack of representational capability and the training
difficulty impede 1-bit CNNs from performing as well as real-valued networks.
We propose Bi-Real net with a novel training algorithm to tackle these two challenges. To
enhance the representational capability, we propagate the real-valued activations generated
by each 1-bit convolution via a parameter-free shortcut. To address the training difficulty,
we propose improved training algorithms targeting the optimization difficulty in 1-bit
convolution networks.
Our Bi-Real Net achieved 56.4% top-1 classification accuracy, which is 10% higher than the
state-of-the-arts (e.g. , XNOR-Net) and proved to be effective on depth estimation task in
real scenarios.
Latent Weights Do Not Exist

The understanding of BNNs, in particular their training algorithms, have been strongly
influenced by knowledge of real-valued networks. Optimization of Binarized Neural Networks
(BNNs) currently relies on real-valued latent weights to accumulate small update steps. In
this study, we argue that these latent weights cannot be treated analogously to weights in
real-valued networks.
We offer a new interpretation of existing deterministic BNN training methods which explains
latent real-valued weights as encoding inertia for the binary weights. Using the concept of
inertia, we gain a better understanding of the role of the optimizer, various
hyperparameters, and regularization.
Binarizing mobilenet via evolution-based searching
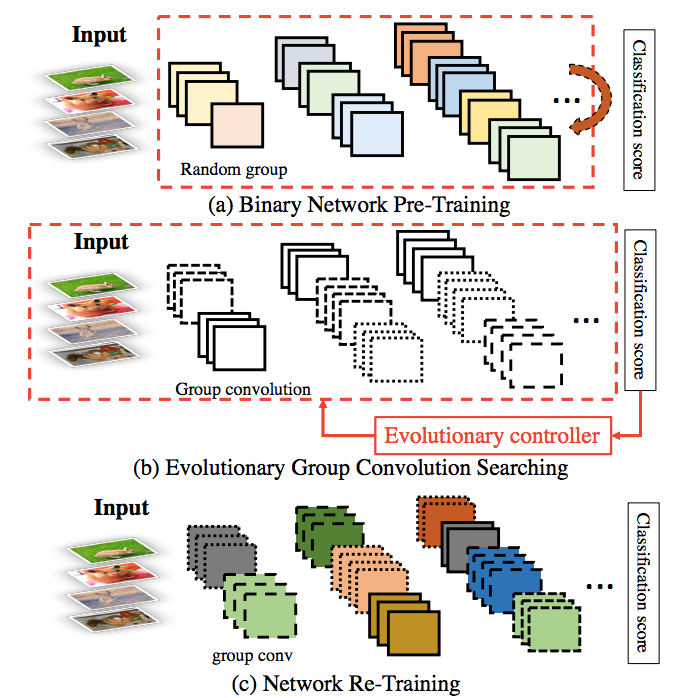
Binary Neural Networks (BNNs), known to be one among the effectively compact network
architectures, have achieved great outcomes in the visual tasks. Designing efficient binary
architectures is not trivial due to the binary nature of the network.
Recent compact network architecture design adopts depth-wise convolution. However,
binarizing depth-wise convolution will result in a lack of representational capability.
Changing depth-wise convolution to vanilla convolutions is too computational costly.
Aiming at leveraging the effectiveness of the heterogeneous group convolution, in this paper
we propose a novel weight-sharing mechanism to explore in group search space optimally
compact binary neural architectures that work efficiently and accurately.
ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions
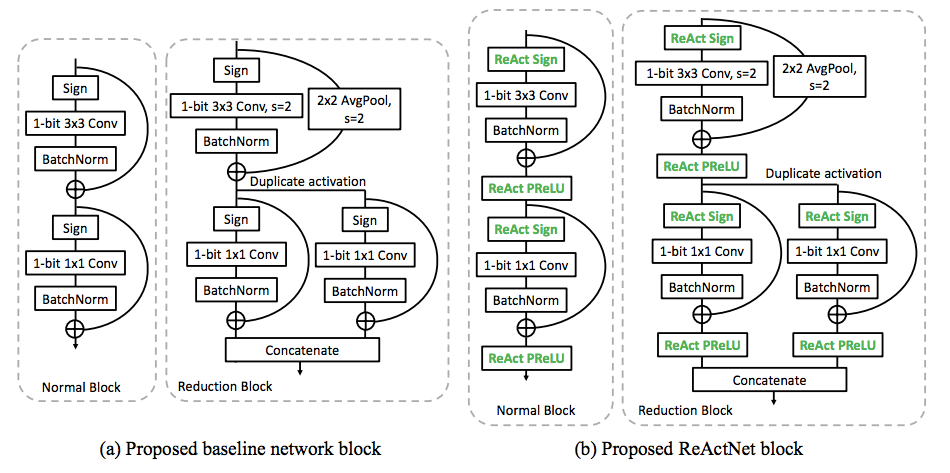
In this paper, we propose several ideas for enhancing a binary network to close its accuracy gap
from real-valued networks without incurring any additional computational cost.
We first construct a baseline network by modifying and binarizing a compact real-valued network with
parameter-free shortcuts, bypassing all the intermediate convolutional layers including the
down-sampling layers. Then, we propose to generalize the traditional Sign and PReLU functions,
denoted as RSign and RPReLU for the respective generalized functions, to enable explicit learning of
the distribution reshape and shift at nearzero extra cost. Lastly, we adopt a distributional loss to
further enforce the binary network to learn similar output distributions as those of a real-valued
network.
We show that after incorporating all these ideas, ReActNet achieves 69.4% top-1 accuracy on
ImageNet, for the first time, exceeding the ResNet-level accuracy (69.3%) while achieving more than
22× reduction in computational complexity.
MetaPruning

Besides binary neural networks, Channel pruning has been recognized as an effective neural
network compression/acceleration method and is widely used in the industry. Conventional
pruning involves substantial human efforts in deciding the layer-wise pruning ratio.
In this work, we adopt evolutionary search to find the best pruning configuration. We
further utilize meta-learning to predict the weights for different pruned networks, which
makes the search process highly efficient.
Compared to the state-of-the-art pruning methods, we have demonstrated superior performances
on MobileNet V1/V2 and ResNet.
Publication:
Zechun Liu, Baoyuan Wu, Wenhan Luo, Xin Yang, Wei Liu, Kwang-Ting Cheng. "Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm." In Proceedings of the European conference on computer vision (ECCV). 2018: 722-737.
Zechun Liu, Wenhan Luo, Baoyuan Wu, Wei Liu, Xin Yang, Kwang-Ting Cheng. "Bi-Real Net: Binarizing Deep Network Towards Real-Network Performance." International Journal of Computer Vision (IJCV), 128(1): 202-219
Koen Helwegen, James Widdicombe, Lukas Geiger, Zechun Liu, Kwang-Ting Cheng, and Roeland Nusselder. "Latent weights do not exist: Rethinking binarized neural network optimization." In Advances in neural information processing systems, (NeurIPS) 2019 pp. 7531-7542.
Phan, Hai*, Zechun Liu*, Dang Huynh, Marios Savvides, Kwang-Ting Cheng, and Zhiqiang Shen. "Binarizing MobileNet via Evolution-based Searching. " In Proceedings of the IEEE International Conference on Computer Vision. (CVPR), 2020
Zechun Liu, Zhiqiang Shen, Marios Savvides, and Kwang-Ting Cheng. "ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions." In Proceedings of the European conference on computer vision (ECCV) 2020
Zechun Liu, Haoyuan Mu, Xiangyu Zhang, Zichao Guo, Xin Yang, Kwang-Ting Cheng, Jian Sun. "MetaPruning: Meta Learning for Automatic Network Channel Pruning." In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2019 (pp. 3296-3305).