
Energy Efficient Bitwise Network Design for Vision Tasks
Large amount of memory and computation in current Convolution Neural Networks (CNNs) impedes their implementation in embedded systems. A bitwise CNN with weights and activations in a convolution layer being either -1 or 1 offers a promising solution to compressing the model size and speeding up inference. But current solution of bitwise CNN encounters an accuracy drop. In order to alleviate that, we proposed to use a shortcut propagating the real-valued information that is already computed in the 1-bit neural network. By further enhancing the training techniques of binary networks, we achieved 56.4% accuracy on ImageNet dataset, much higher than XNOR-net with even fewer real-valued parameters.
Vairation-/Uncertaity-Aware Medical Image Analysis
One reason for the success of deep learning in natural image data is the availability of large-scale labeled data. However, labeled medical image data often is limited, as annotating medical image data requires extensive human efforts and expertise. Consequently, any variation and uncertainty in medical image data would affect the training process, and the capacity of deep learning usually cannot be fully explored. In this project, we propose to improve deep learning performance by addressing variations and uncertainties in medical image data.

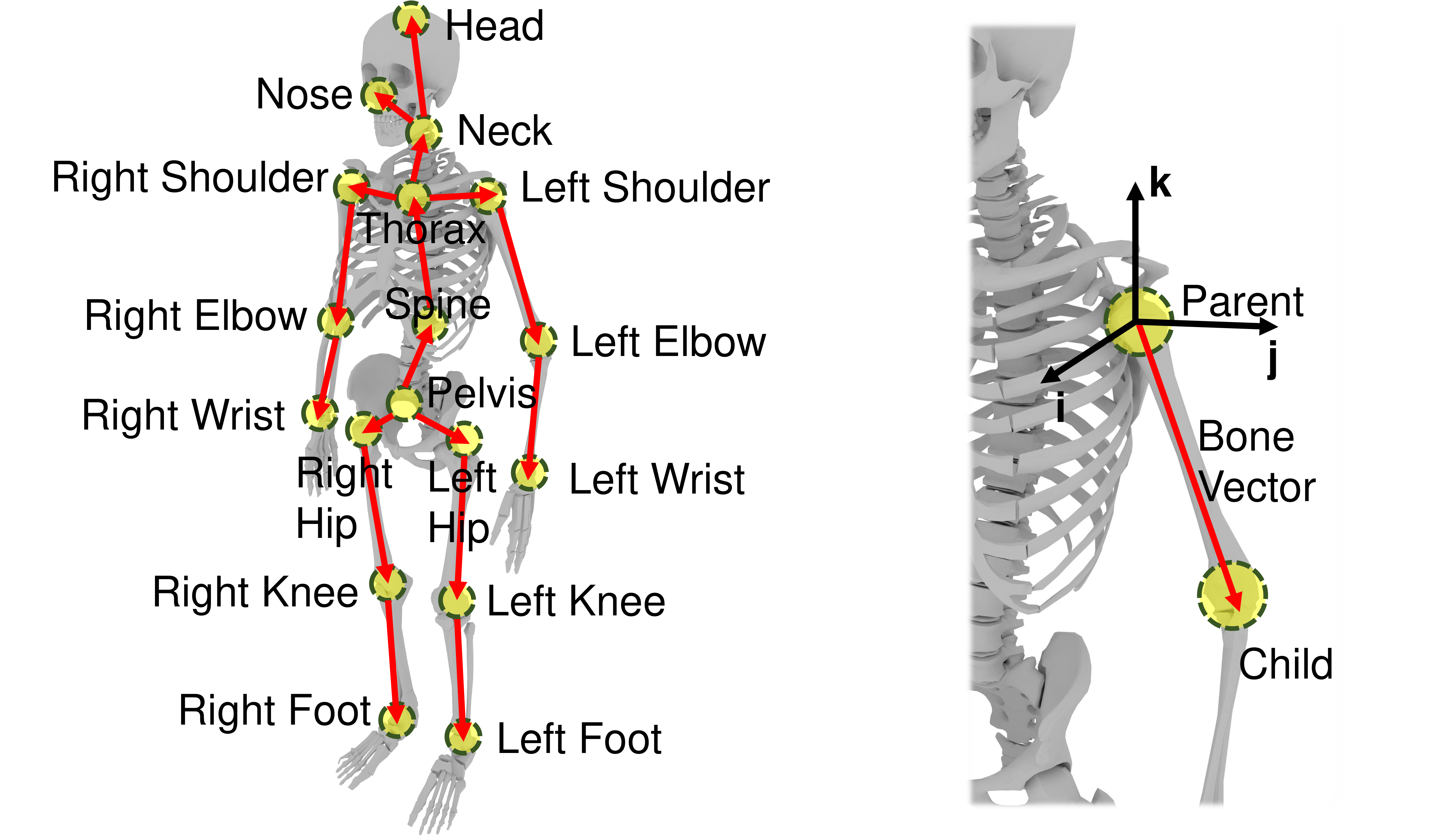
Learning-based Monocular 3D Human Pose Estimation
Obtaining 3D information from RGB images plays a significant role in machine intelligence. This project utilizes machine learning techniques to estimate 3D human pose from a single RGB image. 3D annotation is hard to obtain and can be biased due to the limitation of data collection, which negatively influences model generalization in unseen environments. To cope with this problem, a novel data augmentation approach is proposed to improve model generalization by evolutionary operators. Apart from the data augmentation method, the proposed cascaded model achieves state-of-the-art performance for this task. A new dataset for in-the-wild rare human poses and an interactive annotation tool are released. This work has been accepted by CVPR 2020 as oral presentation. The project website can be reached by clicking the title.

Learning-based Monocular Vehicle Pose Estimation
Accurate perception of vehicle orientation can help autonomous driving systems understand drivers’ intention, as well as help traffic surveillance systems recognize anomalous events. Traditional approaches suffer from the difficulty of approximating a highly nonlinear function that maps pixels to pose vectors. In this work, a novel approach is proposed for vehicle pose estimation with intermediate geometric representations and self-supervision. A monocular vehicle detection and pose estimation system implemented in this work achieved state-of-the-art performance on the KITTI benchmark.
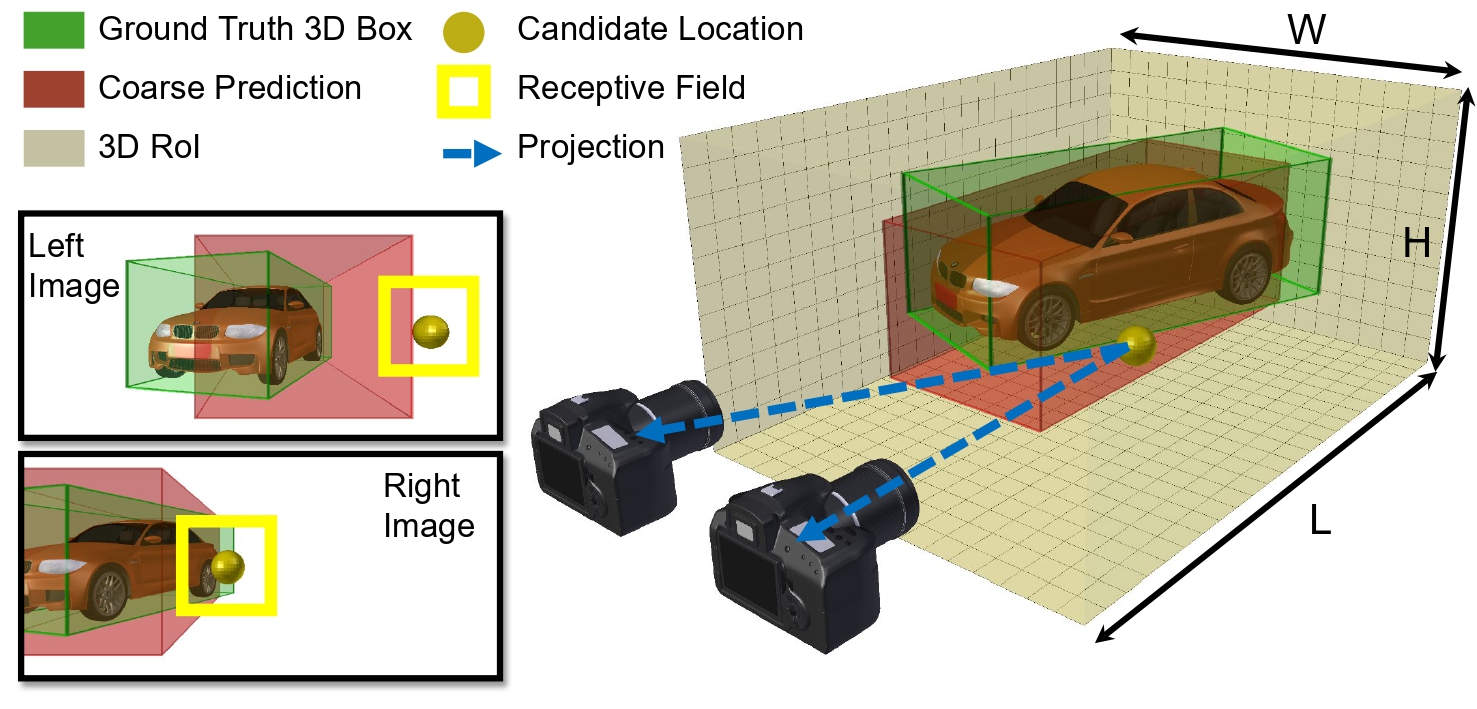
Instance-aware Stereo 3D Object Detection with Multi-resolutional Voxels
Monocular 3D object detection (3DOD) has inferior performance due to the ill-posed nature of the single-view depth estimation problem. Active range sensors like LiDAR are costly. Stereo cameras, simulating a binocular human vision system, are the minimum sensor configuration that can exploit multi-view geometry for more reliable depth inference. In contrast to previous stereo 3DOD approaches that build scene-centric representation with a fixed resolution, this work explores how building multi-resolutional representations with an object-centric view can boost system performance, flexibility, and transferability.
Automated Vision-Based Wellness Analysis of Elderly Care Center Citizens
Elderly care is important yet very expensive to perform. The demand for quality care is increasing but the manpower is not sufficient. Recent Covid-19 pandemic further highlights the gap, where there have been several viral outbreaks in the elderly care-center because workers need to do their shift across care centers. We aim to assist the health workers by providing health insights through automating the wellbeing analysis of elderly citizen from long-term video data.

REDBEE: A Visual-Inertial Drone System for Real-Time Moving Object Detection
Aerial surveillance and monitoring demand both real-time and robust motion detection from a moving camera. Most existing techniques for drones involve sending a video data streams back to a ground station with a high-end desktop computer or server. These methods share one major drawback: data transmission is subjected to considerable delay and possible corruption. Onboard computation can not only overcome the data corruption problem but also increase the range of motion. Unfortunately, due to limited weight-bearing capacity, equipping drones with computing hardware of high processing capability is not feasible. Therefore, developing a motion detection system with real-time performance and high accuracy for drones with limited computing power is highly desirable.

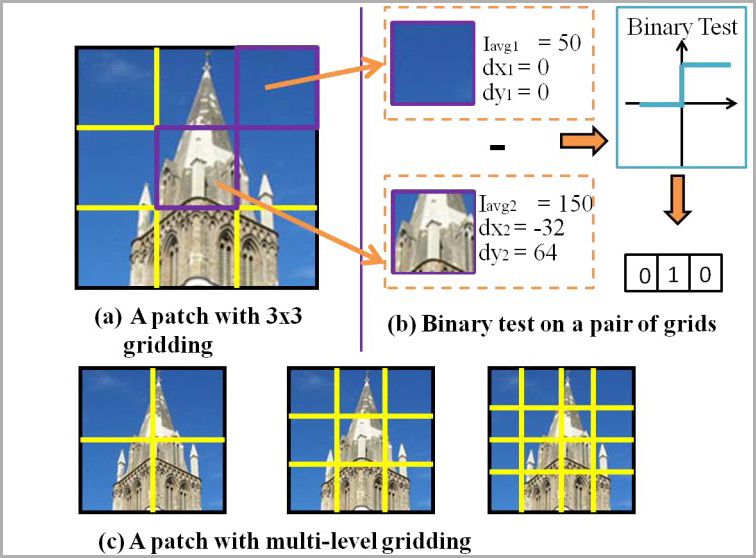
libLDB: A Library for Extracting Ultrafast and Distinctive Binary Feature Description
LDB (Local Difference Binary) is a highly efficient, robust and distinctive binary descriptor. The distinctiveness and robustness of LDB are achieved through 3 steps. First, LDB captures the internal patterns of each image patch through a set of binary tests, each of which compares the average intensity Iavg and first-order gradients, dx and dy, of a pair of image grids within the patch (as shown in (a) and (b)). Second, LDB employs a multiple gridding strategy to capture the structure at different spatial granularities (as shown in (c)). Coarse-level grids can cancel out high-frequency noise while fine-level grids can capture detailed local patterns, thus enhancing distinctiveness. Third, LDB selects a subset of highly-variant and distinctive bits and concatenates them to form a compact and unique LDB descriptor.
Local Feature Descriptor Learning with Adaptive Siamese Network
Although the recent progress in the deep neural network has led to the development of learnable local feature descriptors, there is no explicit answer for estimation of the necessary size of a neural network. Specifically, the local feature is represented in a low dimensional space, so the neural network should have more compact structure. The small networks required for local feature descriptor learning may be sensitive to initial conditions and learning parameters and more likely to become trapped in local minima. In order to address the above problem, we introduce an adaptive pruning Siamese Architecture based on neuron activation to learn local feature descriptors, making the network more computationally efficient with an improved recognition rate over more complex networks.


Drone-based Cinematography
Affordable consumer drones have made capturing aerial footage more convenient and accessible. However, shooting cinematic motion videos using a drone is challenging because it requires users to analyze dynamic scenarios while operating the controller. Our task is to develop an autonomous drone cinematography system to capture cinematic videos of human motion. To the end, we designed two autonomous drone cinematography systems using both heuristic-based methods and learning-based methods.